A significant portion of the open-source software we rely on daily isn’t optimized, or at least not to its full potential. Considering that some code is executed billions of times a day, inefficiencies are a concern. In the past decade, particularly in the last year, our reliance on computers has skyrocketed. This surge in usage has environmental implications, as computers contribute to a non-trivial portion of our overall energy consumption.
While recent attention has focused on Bitcoin’s environmental impact, the energy usage of everyday software, whether in server farms, homes, or offices, continues to rise steadily. Despite the dedicated efforts of many individuals striving to ensure the efficiency of the code that powers our world, what if certain misconceptions are hindering their progress?
Unlocking Software Efficiency With SIMD
SIMD (Single Instruction, Multiple Data) instructions represent a crucial element in optimizing software efficiency across both PCs and mobile devices. However, the challenge lies in their inconsistent utilization across various software applications. While SIMD code can be found in numerous popular code libraries, it’s not always optimized and, in some cases, entirely absent. This inconsistency underscores the need for broader adoption and optimization of SIMD instructions to unlock the full potential of software performance on diverse computing platforms.
Frequently, developers have made strides to incorporate optimized SIMD code into libraries, yet it remains unfinished or suboptimal. This situation can be particularly frustrating because it requires placing implicit trust in the authors of SIMD code. Harnessing the full potential of CPU vector capabilities demands additional expertise, and this reliance inherently assumes that these authors possess the necessary skills to craft efficient code. The gap between expectation and reality underscores the importance of meticulous attention to detail and continuous refinement in optimizing SIMD implementations within code libraries.
Revitalizing SIMD Implementations
The discovery of inefficient code in widely used libraries often compels a desire to contribute and improve. Furthermore, the static nature of SIMD code within open-source libraries exacerbates this concern. Once an optimal SIMD implementation is achieved, it tends to remain untouched indefinitely. This stagnation can be disheartening, as it suggests missed opportunities for ongoing optimization and enhancement. Recognizing this trend underscores the importance of fostering a culture of continuous improvement within the open-source community, where regular reviews and updates ensure that SIMD implementations remain current, efficient, and responsive to evolving computing environments.
The purpose of this blog post is twofold: to shed light on the need for additional optimization efforts in critical libraries and to highlight a programming concept that often goes unnoticed - the potential for SIMD code to accelerate “single-lane” algorithms. It’s worth noting that C compilers sometimes generate single-lane SIMD code automatically. However, there’s a compelling case for manual authoring of SIMD intrinsics when circumstances dictate. By doing so, developers can harness the full power of SIMD technology to optimize performance, even in scenarios traditionally associated with single-lane processing. This approach not only maximizes computational efficiency but also underscores the importance of leveraging advanced programming techniques to extract optimal performance from modern hardware architectures.
The Missing SIMD Code in libPNG
In this article, I’ll delve into the notable absence of SIMD code in libPNG. Despite its critical importance and widespread usage by billions of individuals on a daily basis, this library has endured with suboptimal code for several years. While the flate or deflate code accounts for the bulk of processing time in PNG encoding and decoding for most images, the image filters also play a significant role and present an opportunity for optimization with SIMD. By addressing this oversight, we can enhance the performance and efficiency of libPNG, ultimately benefiting countless users worldwide.
PNG filters play a crucial role in enhancing data compressibility by leveraging repeating patterns to reduce the total number of unique symbols for compression. In essence, these filters aim to transform much of the image data into zeros by replacing pixel values with the differences between them and their neighbors. By generating clusters of zeros, the filtered data becomes more compressible compared to its unfiltered counterpart.
In 2016, efforts were made to optimize libpng using SIMD instructions. However, the authors halted short of implementing SIMD versions for all filter functions, citing a perceived lack of necessity. This decision stemmed from a mistaken assumption. I strongly believed that SIMD could indeed accelerate the functions deemed unworthy of manual optimization.
The Hard Work
I selected a sizable grayscale PNG file measuring 10,000 by 10,000 pixels to evaluate decoding speed. Opting for a larger image facilitates clearer insights into where time is allocated during profiling. To conduct my tests, I devised a straightforward test program that decodes the image iteratively 20 times. By activating the SSE4.1 vector extensions in Xcode and enabling the SIMD optimized filters within the libpng build configuration, I prepared the environment for testing. Now, it’s time to execute the test image in the profiler and scrutinize the results.
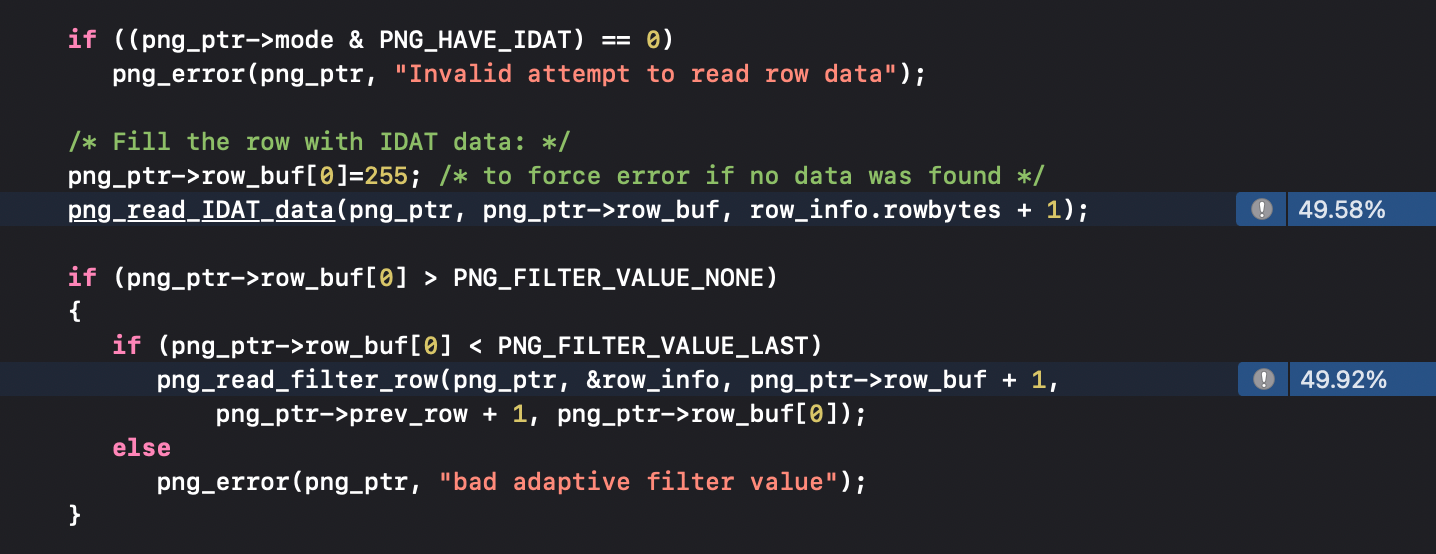
As previously mentioned, the filtering stage can consume a significant amount of time during decoding. In this scenario, approximately 50% of the decoding time is allocated to the inflate process, while the remaining 50% is dedicated to the de-filtering step. This distribution appeared disproportionate, especially considering the activation of SIMD code. To investigate further, I meticulously examined the filter setup code and identified the following issue:
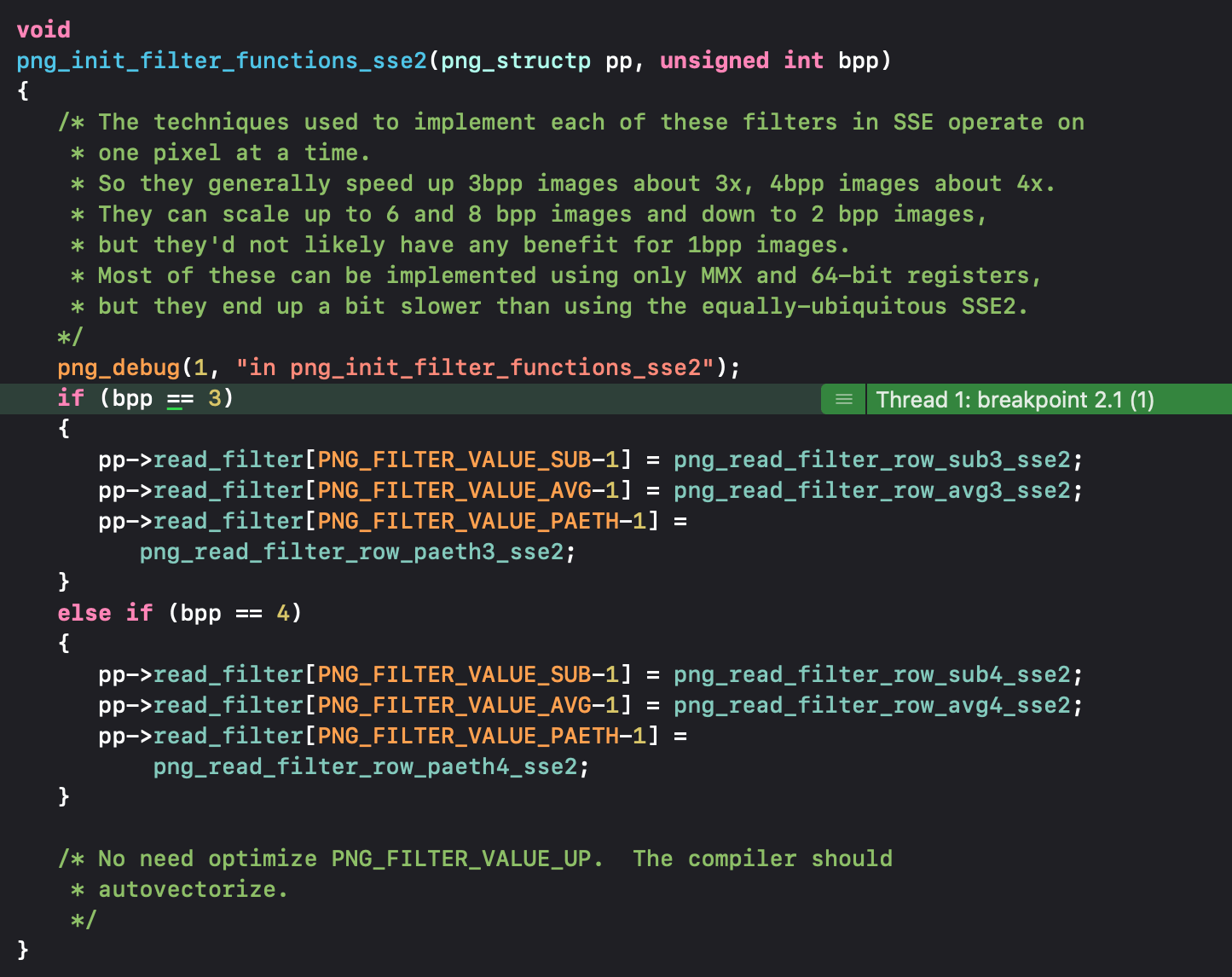
It appears that SIMD code has not been implemented for PNG files with one byte per pixel, including grayscale or palette color pixels. Additionally, there are unoptimized filters for every pixel type. The variable bpp in the code snippet provided indicates the number of bytes per pixel. With the assistance of the profiler, we can delve deeper into these issues to identify areas for improvement and optimization.

It’s evident from the profiler results that the Paeth filter is consuming more time than the inflate code, which is a concerning inefficiency. To address this issue, let’s embark on crafting an optimized Paeth filter to enhance performance. By optimizing this specific filter, we aim to reduce its execution time and consequently improve the overall efficiency of PNG decoding. Let’s proceed with writing and implementing the optimized Paeth filter and observe how it impacts performance.

The significant speed improvement achieved by the SIMD Paeth filter is indeed remarkable, resulting in approximately a 20% reduction in total decode time. To understand why I was confident about the potential for speed gains with a SIMD implementation on x86, despite the Paeth filter requiring processing of one pixel at a time, let’s delve into a few key factors:
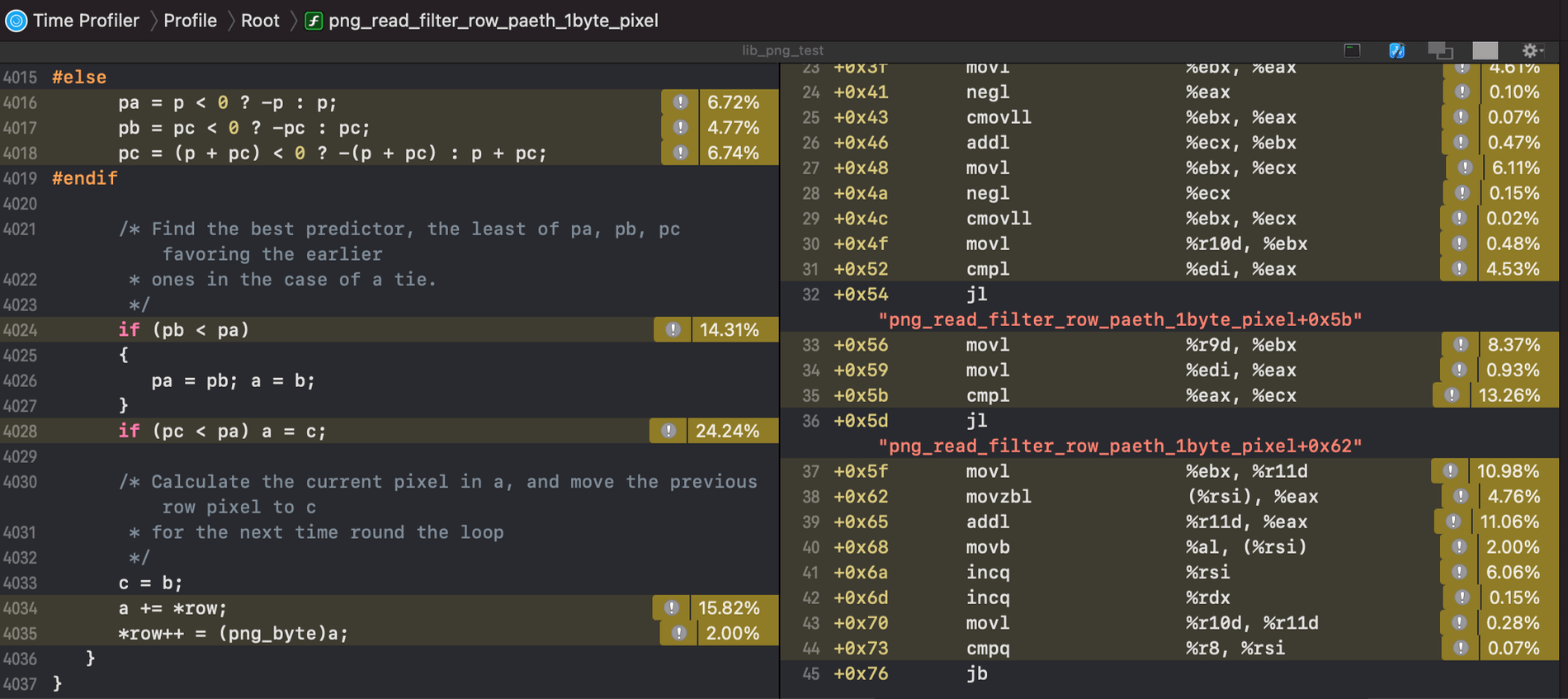
This snippet showcases the original Paeth filter code. On the right column, you’ll find the x64 assembly language generated by the compiler when configured for maximum optimization (-O3). Upon review, I immediately identified three areas where enhancements could be made on x86 architecture through the utilization of SIMD code:
- There isn't a scalar instruction specifically designed for calculating the absolute value, hence the code resorts to a negate and conditional move sequence. This can be observed from line 23 onwards, where a 3-instruction sequence is utilized to achieve the absolute value computation.
- Scalar instructions lack a direct means of handling conditional statements without resorting to branching. From line 31, you'll notice a comparison followed by a "jl - jump if less" instruction. However, branching operations can be costly on a pipelined CPU architecture.
- Furthermore, the inefficiency of reading and writing one byte at a time is evident from lines 37 to 40. While scalar code can access memory up to the native integer size (64-bits), SIMD maintains an advantage with 128-bit access. In modern Intel CPUs, memory access tends to be much slower than instruction execution, even when the memory is sourced from L0 cache. Although memory access latency may vary (e.g., Apple M1 exhibits low memory latency), this characteristic is typically consistent across mobile and desktop CPUs.
Below is a portion of the SSE2 code I developed for the Paeth filter. While newer instructions like AVX2 could streamline this process slightly, I’ve found that the compiler is adept at optimizing certain intrinsics. While there’s room for further improvement, it’s remarkable how much faster this implementation is compared to the scalar code.
The calculations involve carrying a 16-bit value from the 8-bit pixel differences. To address this, I treated all pixel data as 16-bit by expanding it with _mm_unpacklo_epi8. Additionally, I preloaded the next 8 pixels to help mitigate some of the memory latency:
xmmB = _mm_loadu_si128((__m128i*)prev); // B's & C's (previous line)
xmmRow = xmmRowNext;
xmmRowNext = _mm_loadu_si128((__m128i*)&row[8]); // current pixels
xmmC = _mm_unpacklo_epi8(xmmB, _mm_setzero_si128());
xmmB = _mm_unpacklo_epi8(_mm_srli_si128(xmmB, 1), _mm_setzero_si128());
// a &= 0xff; /* From previous iteration or start */
xmmA = _mm_unpacklo_epi8(xmmRow, _mm_setzero_si128());
xmmRow = _mm_unpacklo_epi8(_mm_srli_si128(xmmRow, 1), _mm_setzero_si128());
xmmP = _mm_sub_epi16(xmmB, xmmC); // p = b - cAfter reading the 8 pixels, I iterate over them and shift everything down by one pixel during each iteration. Subsequently, each processed pixel is extracted from one register and inserted into another. To minimize the register usage, I devised a rotated right (ROR) operation on SIMD registers using the _mm_shuffle_epi8 instruction with the following byte pattern:
// shuffle mask to rotate right (ROR)
xmmRotate = _mm_set_epi8(1, 0, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2);At the conclusion of the loop, I consolidate the 8 completed 16-bit pixels back into bytes and write them to the output. This final step ensures that the processed image data is properly formatted and ready for output.
xmmRow = _mm_packus_epi16(xmmA, xmmA);
// Need to insert the next finished pixel into the prefetched next set of 8
xmmRowNext = _mm_insert_epi8(xmmRowNext, _mm_extract_epi8(xmmA, 14), 0);
_mm_storel_epi64((__m128i*)&row[1], xmmRow);A significant challenge in this code arises from the interdependence of each pixel on the previously generated one. As we transition from processing one set of 8 pixels to the next, it becomes necessary to transfer the last finished pixel into the newly read (unfiltered) pixels for the next iteration of the loop. This process ensures the continuity of pixel calculations and maintains the integrity of the image data as we progress through each set of pixels.
Harnessing Intel’s Enhanced SIMD Instructions
Each succeeding generation of Intel CPUs introduces new instructions, primarily focusing on SIMD enhancements. These additions expand the capabilities of SIMD processing, enabling more efficient parallelization of tasks. Notably, scalar instructions, such as absolute value operations, remain exclusive to SIMD instruction sets.
Consequently, leveraging SIMD instructions becomes increasingly vital for maximizing computational efficiency and performance gains on modern Intel CPU architectures.
Wrapping Up
The decision to write a blog post rather than just submitting a pull request for this code stemmed from a desire to challenge and potentially break long-held assumptions. A classic example of this phenomenon is the 4-minute mile, where for years, it was widely believed that running a mile in under 4 minutes was impossible—until Roger Bannister shattered that assumption in 1954. Similarly, if C compilers can gain a speed advantage by utilizing SIMD instructions for “single-lane” code, why can’t programmers achieve similar benefits through hand-written intrinsics?
By raising awareness about this concept, I hope to inspire fellow programmers to explore and experiment with the idea of leveraging SIMD instructions for single-lane code. Perhaps by doing so, we can challenge and ultimately break other long-standing assumptions, leading to new discoveries and advancements in software optimization and performance enhancement.