Since its release in 1992, the JPEG standard has become synonymous with digital photography, finding its way into nearly every application that deals with high-quality images. Its rapid and widespread adoption can be attributed to its utilization of multiple techniques to efficiently reduce file sizes. Among these techniques is a keen understanding of the human visual system’s limitations, distinguishing between crucial information to preserve and less important details that can be safely removed.
The JPEG Coding Algorithm
To compress an image using the JPEG method, several steps are involved, as illustrated in the image below. Initially, the image is typically converted from RGB to the YCbCr color space. This conversion is essential to enable sub-sampling of pixels. Since the human eye is more sensitive to changes in luminance than in chrominance, this process allows the chroma channels to be downsampled while maintaining the luma channel at full resolution. Remarkably, even with a 50% reduction in data, the perceived degradation in image quality is minimal.
Next, the image is segmented into 8x8 MCUs (Minimum Coded Units), analogous to Macro Blocks in video codecs. These MCUs consist of square blocks of pixels compressed based on their similarity to one another. Within each MCU, the pixels undergo a transformation from the spatial domain to the frequency domain using a Discrete Cosine Transform (DCT). This transformation facilitates the removal of high-frequency information (fine detail), thereby further compressing the image. The degree to which high-frequency coefficients are eliminated determines the file size and the resulting level of image blur. This mechanism effectively regulates the “Q Value” or compression amount utilized by encoders.
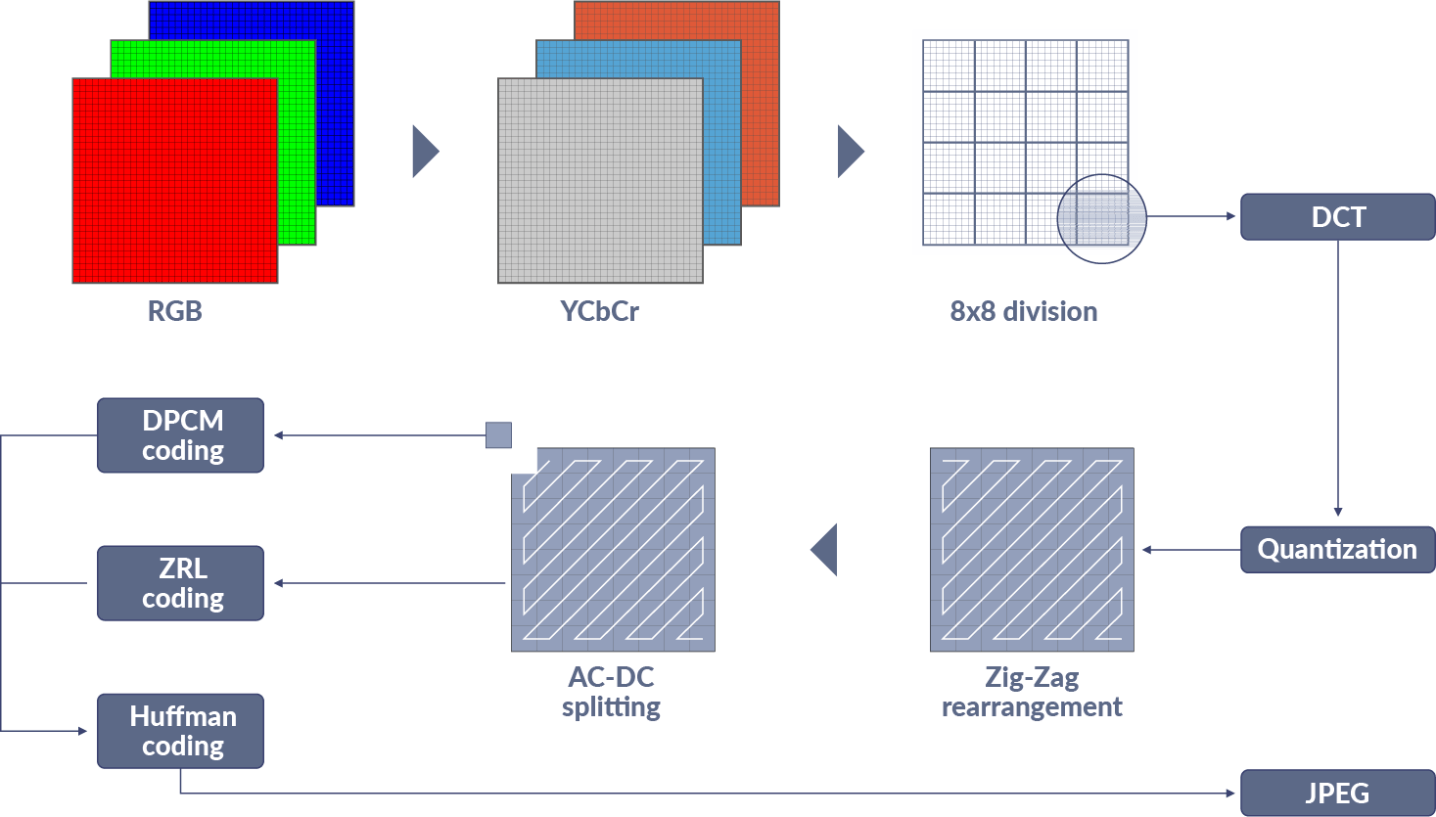
One of the ingenious ideas integrated into the standard is leveraging the similarity in DC value (essentially brightness) between adjacent MCUs to further reduce data size. Instead of encoding the entire value, only the change from one MCU to the next is compressed, as depicted in the “DPCM coding” block above. While this approach offers significant benefits, it also presents a minor challenge. Since each successive MCU’s DC value(s) depends on a delta from the previous one, any data error can cascade, causing all subsequent MCUs to be incorrect.
Compounding this issue is the use of Variable Length Codes (VLC) for the compressed symbols that encode the image data (shown as “Huffman coding” above). With VLC, a single incorrect bit can corrupt the data from that point onward. In the early days of JPEG’s inception, this was a genuine concern, as images were often transmitted over channels (e.g., acoustic modem) lacking robust error correction or stored on error-prone media (e.g., floppy disks).
In response to this potential vulnerability, the standard introduced a feature to mitigate the impact of data corruption on the image. This feature involves periodically resetting the previous DC value to 0, prompting the next MCU to encode its entire value as a delta from 0. Consequently, any corrupted DC values will only affect pixels up to the next restart point.
This mitigation technique is implemented using Restart Markers, which are 2-byte markers inserted between the MCUs at regular intervals (e.g., every 100 MCUs). In the event of data corruption, locating the next restart marker (JPEG markers are always on byte boundaries and preceded by 0xFF) allows for scanning forward in the file. Once the next restart marker is identified, the image can be accurately decoded from that point onward, leveraging the known number of MCUs between each restart marker.
The Ever Evolving Use of Digital Images
Following the release of the JPEG standard, advancements in computer networks and storage rapidly improved reliability, incorporating error detection and correction mechanisms such as TCP/IP. Additionally, solid-state storage cards utilized in digital cameras demonstrated high reliability, leading to a period where restart markers were largely overlooked. Although they slightly increased file size, their perceived benefits were minimal.
During this era, computer software primarily operated on single processors, executing single-threaded processes. Consequently, the need for JPEG images to be decoded in a single pass, due to their utilization of variable-length codes and successive delta values for MCUs, posed no significant issues as software was designed to function as a single thread.
However, in recent years, significant shifts have occurred in computing environments and the usage of JPEG images. Virtually every computing device now boasts multiple CPUs and runs operating systems with multiple threads, even smartphones. Moreover, individuals are capturing, editing, and viewing billions of JPEG photos on their mobile devices, with each new generation of phones producing larger and higher-resolution images.
For professionals handling vast quantities of photos, the time required to encode and decode images has become increasingly critical. This heightened importance is driven by the sheer volume and size of new images being generated, emphasizing the need for optimized processing workflows.

Repurposing a Good Idea Into An Even Better Idea
Computers have experienced a consistent trajectory of improvement since the 1970s, largely driven by advancements in silicon processing. Moore’s Law, coined to commemorate Gordon Moore’s prediction of doubling transistor counts every 18 months, has held true for transistor counts, albeit encountering limitations in computer speed due to physical constraints and power-related issues.
Given the plateau in individual processor speed, contemporary computing focuses on leveraging multiple processors to expedite tasks through parallel processing. The ability to divide tasks into segments and distribute them across multiple CPUs is advantageous in today’s computing landscape. However, not all tasks lend themselves to parallelization, especially those with dependencies between successive components, such as JPEG encoding and decoding.
Yet, restart markers present a convenient solution. They reset the VLC data and MCU DC delta value to byte boundaries, enabling the division of JPEG encoding and decoding tasks into multiple threads. For encoding, the image can be divided into symmetrical strips, with each strip processed by a separate processor. Upon completion, the outputs are seamlessly combined using restart markers. Similarly, decoding tasks can be distributed among processors corresponding to the number of restart markers. The only additional effort required is scanning forward in the compressed data to locate restart markers, as JPEG files lack a directory indicating their positions.
Real World Example
In multi-threaded applications, performance often fails to scale linearly with the number of CPUs employed. Simply splitting a task into 12 threads to utilize 12 CPU cores doesn’t guarantee a 12-fold speed increase. Additional overhead is incurred in managing threads, and memory typically remains a single entity shared among processors.
To illustrate this, let’s conduct a test using the following image:

At Optidash, we leverage various techniques, including the utilization of restart markers, to significantly enhance the speed of both image decoding and encoding processes. We recently conducted a test using the image above on a 2018 MacBook Pro 15” laptop equipped with a 6-core Intel i7 processor. Here are the results:
| Number of CPUs | Image decode time | Image encode time |
| 1 | 53ms | 264ms |
| 3 | 25ms | 104ms |
| 6 | 18ms | 61ms |
As depicted in the table above, dividing JPEG coding into multiple segments and distributing them across different CPUs yields a measurable advantage. However, the speed increase often deviates from linear scaling when employing additional CPUs. This disparity arises due to the intensive memory usage, which constrains the extent to which multiple CPUs can enhance overall speed.
Here’s a simplified pseudocode outlining the structure of a multi-threaded JPEG encoder:
void ThreadedWriteJPEG(assorted JPEG parameters, int numThreads) {
int slice;
pthread_t tinfo;
// set completion counter
sliceRemaining = numThreads;
// Start a thread for each slice
for (slice = 0; slice < numThreads; slice++) {
pthread_t tinfo;
// Use a 'slice' structure to hold info about each thread’s work
// This includes a pointer to the start of that strip of pixels
// and the number of lines to compress
<setup slice structure for each thread's work>
pthread_create(&tinfo, NULL, JPEGBuffer, &slices[slice]);
} // for each slice
// wait for all worker threads to finish
WaitForThreads(&sliceRemaining);
// merge slices into a single file and write it
WriteJPEGBuffer(slices, numThreads);
}